Hey all,
Keep getting kernel panics and reboots on my 2.0 server due to random memory issues. It seems that once I get close to 100% memory usage for a few days, I hit a bad memory module and the server crashes. Any help would be much appreciated! For reference, here’s my build: Anniversary SNAFU 2.0 Example Build (Virtualization)
I currently have 128GB installed. Here’s what I have installed:
- Samsung 64GB (8x8GB) 2Rx4 PC3-10600R DDR3 ECC REG Server Memory (M393B1K70DH0)
- Samsung M393B1K70CHD-YH9 8GB PC3L-10600R Server DIMM
I’m currently running promox on this host with zfs datasets for data and boot disks. As the memory usage comes up, when it gets near 100% for a few days, I’ll get the following errors and will lock up until I reboot it. Here’s what I can see:
# Memory errors
kernel: [137160.613217] EDAC MC1: 2 CE memory read error on CPU_SrcID#1_Ha#0_Chan#0_DIMM#0 (channel:0 slot:0 page:0x1bbefd6 offset:0x700 grain:32 syndrome:0x0 - OVERFLOW area:DRAM err_code:0001:0092 socket:1 ha:0 channel_mask:1 rank:1)
kernel: [137160.697675] EDAC MC1: 2 CE memory read error on CPU_SrcID#1_Ha#0_Chan#1_DIMM#0 (channel:1 slot:0 page:0x1bbefd6 offset:0x740 grain:32 syndrome:0x0 - OVERFLOW area:DRAM err_code:0001:0092 socket:1 ha:0 channel_mask:2 rank:1)
$ ras-mc-ctl --guess-labels
memory stick 'P1_DIMMA1' is located at 'Node0_Bank0'
memory stick 'P1_DIMMA2' is located at 'Node0_Bank0'
memory stick 'P1_DIMMB1' is located at 'Node0_Bank0'
memory stick 'P1_DIMMB2' is located at 'Node0_Bank0'
memory stick 'P1_DIMMC1' is located at 'Node0_Bank0'
memory stick 'P1_DIMMC2' is located at 'Node0_Bank0'
memory stick 'P1_DIMMD1' is located at 'Node0_Bank0'
memory stick 'P1_DIMMD2' is located at 'Node0_Bank0'
memory stick 'P2_DIMME1' is located at 'Node1_Bank0'
memory stick 'P2_DIMME2' is located at 'Node1_Bank0'
memory stick 'P2_DIMMF1' is located at 'Node1_Bank0'
memory stick 'P2_DIMMF2' is located at 'Node1_Bank0'
memory stick 'P2_DIMMG1' is located at 'Node1_Bank0'
memory stick 'P2_DIMMG2' is located at 'Node1_Bank0'
memory stick 'P2_DIMMH1' is located at 'Node1_Bank0'
memory stick 'P2_DIMMH2' is located at 'Node1_Bank0'
maybe?
CPU_SrcID#1_Ha#0_Chan#0_DIMM#0
CPU_SrcID#1_Ha#0_Chan#1_DIMM#0
memory stick 'P1_DIMMA1' is located at 'Node0_Bank0'
memory stick 'P2_DIMME2' is located at 'Node1_Bank0'
Here’s an example of one whole memory error chunk out of the kernel log:
kernel: [137160.612524] mce: [Hardware Error]: Machine check events logged
kernel: [137160.613203] EDAC sbridge MC1: HANDLING MCE MEMORY ERROR
kernel: [137160.613204] EDAC sbridge MC1: CPU 8: Machine Check Event: 0 Bank 7: cc00008000010092
kernel: [137160.613205] EDAC sbridge MC1: TSC 4ac7411cc9a75
kernel: [137160.613205] EDAC sbridge MC1: ADDR 1bbefd6700
kernel: [137160.613206] EDAC sbridge MC1: MISC 424c8086
kernel: [137160.613207] EDAC sbridge MC1: PROCESSOR 0:306e4 TIME 1619851803 SOCKET 1 APIC 20
kernel: [137160.613217] EDAC MC1: 2 CE memory read error on CPU_SrcID#1_Ha#0_Chan#0_DIMM#0 (channel:0 slot:0 page:0x1bbefd6 offset:0x700 grain:32 syndrome:0x0 - OVERFLOW area:DRAM err_code:0001:0092 socket:1 ha:0 channel_mask:1 rank:1)
kernel: [137160.697023] mce: [Hardware Error]: Machine check events logged
kernel: [137160.697661] EDAC sbridge MC1: HANDLING MCE MEMORY ERROR
kernel: [137160.697663] EDAC sbridge MC1: CPU 8: Machine Check Event: 0 Bank 7: cc00008000010092
kernel: [137160.697663] EDAC sbridge MC1: TSC 4ac74191fdc4f
kernel: [137160.697664] EDAC sbridge MC1: ADDR 1bbefd6740
kernel: [137160.697664] EDAC sbridge MC1: MISC 425a3a86
kernel: [137160.697665] EDAC sbridge MC1: PROCESSOR 0:306e4 TIME 1619851803 SOCKET 1 APIC 20
I’ve tried searching the contents of dmidecode -t memory | less and searching for that memory address, but it’s not all that helpful.
Is there any simple way to identify the bad module from this information? I found a pretty helpful article, but am struggling to compute the memory hex ranges that this error is occurring within. https://forums.centos.org/viewtopic.php?t=68484
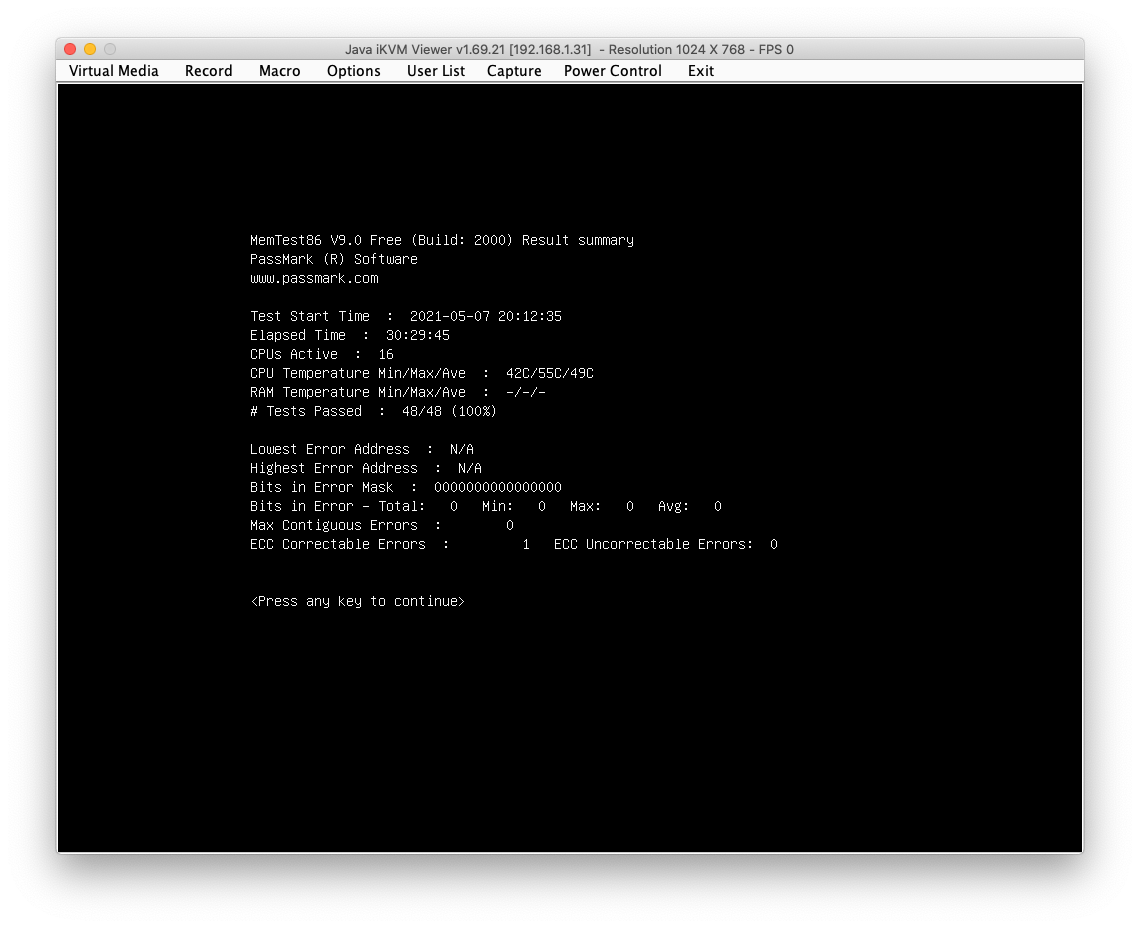
I’d prefer not to reboot and run memtest86 for eons to figure out that the memory is bad since I already know there is a bad memory module, I just need to figure out which one.
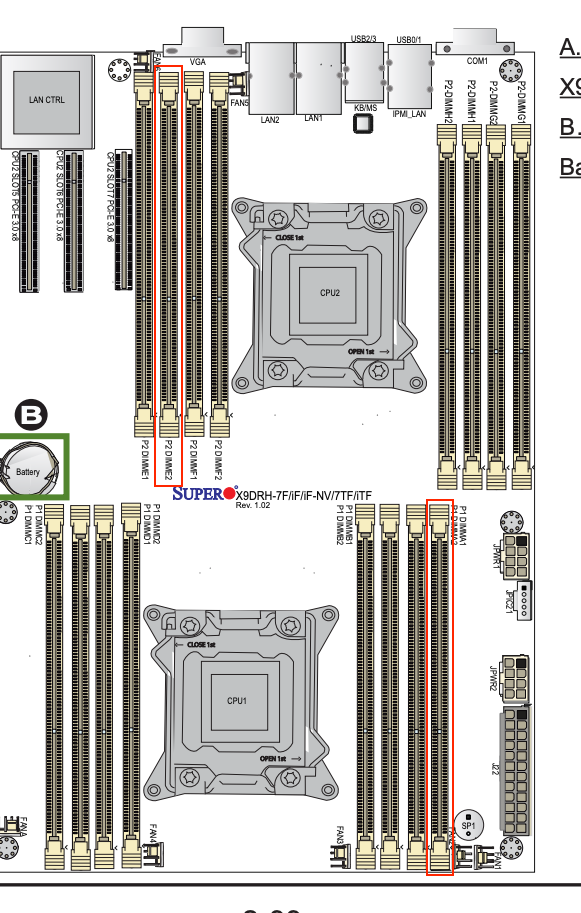
This is what I’m thinking I should try to swap out, but I’d like a second set of eyes…
Any ideas?